
A new semantic chunking approach to RAG
Using the shape of stories

As we saw in my last blog post, there is a shape for stories.
The next question we need to ask is, if the stories have a shape, can we use that information to make RAG better. Turns out we can. Lets see.
The shape of the stories helps us in chunking, which is a major problem area in RAG.
Chunking is one problem with RAG. Too big a chunk, you lose specificity. Too small a chunk, you lose context. What's the right size. This is the problem we try to solve by understanding the "shape of stories". Use the change in latent space to decide context change.
Semantic chunking has been tried before and is available in frameworks like LlamaIndex. But I wanted to get a better feel for the chunking.
Lets have a look at some stories:
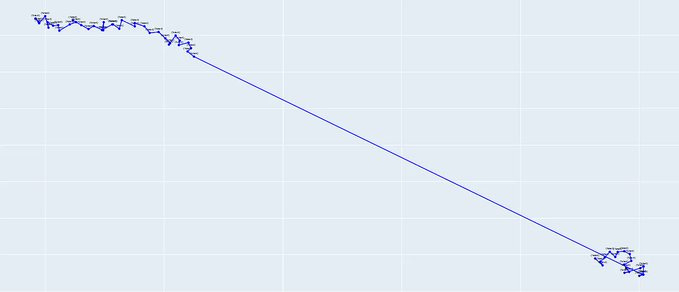
Here we can clearly see we can have two chunks.
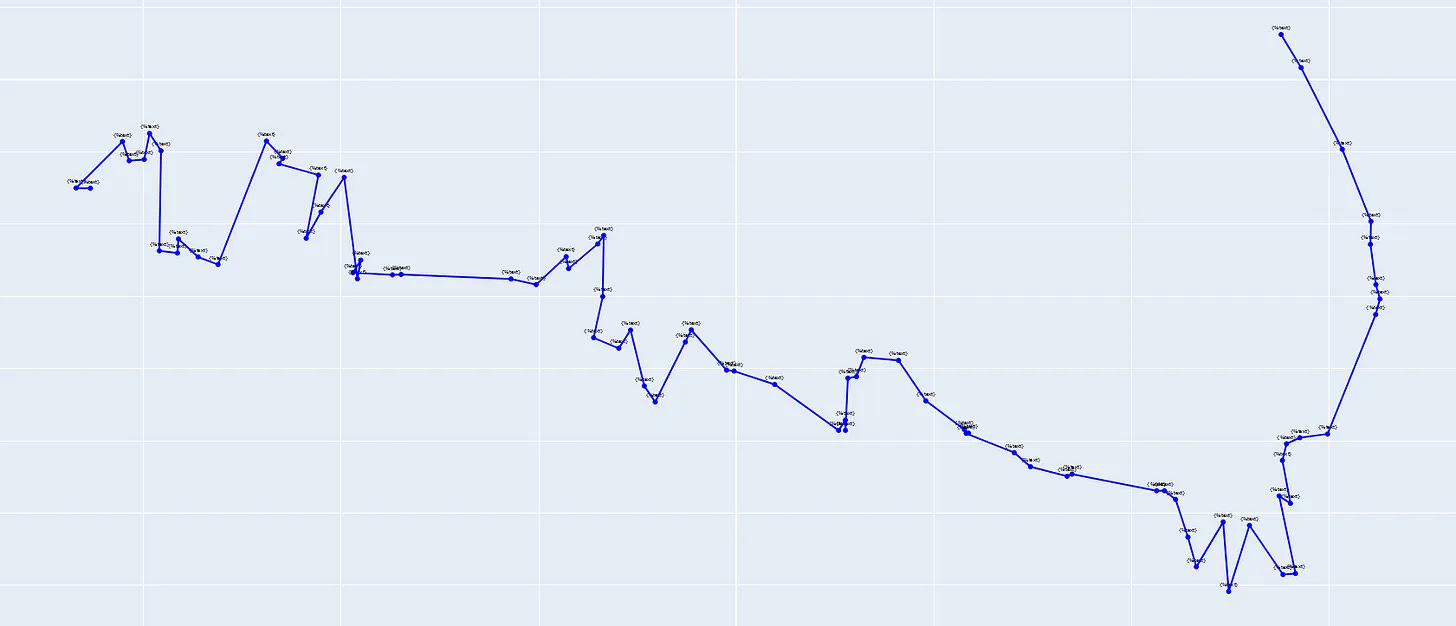
This one is alittle harder, but if we zoom in, we can keep some thresholds and find a jump. Whenever there is a jump in the latent space, we can chunk.
The important part is identifying “what”, the jump is.
It can be as simple as the distance measure. Or we can look at the slope etc.
We have experimented with this and are releasing an API that you can explore to see if this chunking strategy works for you.
A comparison of the semantic chunking in Llamaindex to our chunking is given below
The chunking was done on Paul Grahams essay.


All the chunks for the essay can be found in this gist.
As you can see, our chunking has much more cleaner topics whereas the default semantic chunking bunches a bunch of topics into one chunk. Read the essay and chunk it manually and compare :)
Disclaimer: This is not a research proof idea. Me and my team have not done rigorous benchmarking of this approach. We use this approach in our RAG pipeline and have gotten some good results. Please feel free to try this out and share your comments.
What is RAG?