
AI and the art of doing with little-Part 1
GPUs, data everything is needed in large amounts. Can we do better?

We are in the age of LLMs. Unfortunately LLMs need huge compute. And huge data. Both are costly to get. And in the case of GPUs, even nations are fighting over who gets access first. What this means is that if you have to win the AI race, you need to have money.
And this is the reason, if you ask anyone, who has the most impact on the future of AI, most probably the answer you will get is Sam Altman.
Sam Altman? Why? He is not even an AI expert. But hey, he has been able to consolidate the money allocated to AI by the world. And thats why he is the most powerful. This need not be the case. In a series of articles, I will try to put forth different ideas on how we can attack the problem of money in AI. This is especially true for businesses from India building on AI.
First, let me talk a little bit about my inspiration. One of the books which which was very influential in my thought process was “The Tell-Tale Brain” by V. S. Ramachandran

{kind=link}
I will quote verbatim some snippets from the book and will link it to how it maps to research on AI and LLMs.
“But I feel complled to mention my early romance with 19th century science because it was a formative influence in my style of thinking and cinducting research. Simply put, this style emphasizes conceptually simple and easy to do experiments.”
Personally, I have also always gravitated towards easy to do experiments which open up minds, like the experiment Faraday did by putting a magnet behind a paper and throw iron filings on the paper to render the magnetic field visible. As V.S. Ramachandran says, the experiments should be so simple that any school kid should be able to do it.
For me, the current approaches of deep learning fail this test.
I know, I know, people will say that this was ok for 19th century science and not in this era of big science.
Well, guess what? V.S. Ramachandran(VSR) has an answer for that too:


This is exactly the argument the “big AI” companies are making. This technology is “big science”, so major advances can only be made by large teams employing “high tech machines”(GPUs).
Well, I too disagree like VSR above. And for me also, “small science” is much more fun and has turned up big discoveries. And just like VSR used just q-tips and mirrors to understand the human brain, I am sure we will also find(I believe we already have, but that’s for another blog) some algorithm which will crack open learning in AI in much cleaner fashion.
As I have mentioned in my earlier articles, the biggest technological advancement ChatGPT has done is to prove that given enough data, we can predict the next token with great accuracy and by predicting the next token, magic happens.
So that means that lets say we have a billion sentences(everything ever written etc). That’s our training set. We have to use that and predict the next token given a set of context tokens.
Transformers have proven that they can do it by training using lots of GPUs for lots of time. But I refuse to accept that that is the only way. People are already looking at the problem in new ways. I will present some of the ways we are trying more in detail in upcoming articles. But just for fun, lets think of another way of imagining this problem.
Lets say each sentence or paragraph is a path. You start with the first word. Then you jump to the next word and keep on going until you finish the sentence. You have a billion paths like this.
Now you have started on a new path and jumped across 4 words. What should I do next? Which next hop should I take? What data structures can we use to represent this? What algorithms can be used to solve this?
I am not saying this will solve the next word problem without using transformers and GPUs. I am just saying it’s fun to imagine cleaner better “small” solutions instead of just accepting that there is only one way.
Once again, we have a VSR quote from the book :)
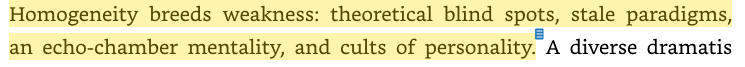

Now, replace high tech brain scanners in the above paragraph with GPUs, and that will explain exactly what I am talking about.
In the next article I will write about some innovative approaches we have taken to solve the data problem. How can we use the youth of India and create open source datasets that can help all researchers.