
Building a vector database in 2GB for 36 million Wikipedia passages

Wikipedia neural search running on a laptop(2GB small model and 10GB large model).
https://speech-kws.ozonetel.com/wiki
Thanks to @CohereAI for releasing the Wikipedia embedding dataset. I saw that for 36 million passages the embedding size would be around 120 GB. So if I had to host the embeddings and enable neural search on this dataset I will have to do LLM ops and run vectorDB clusters. A quick search on Pinecone shows that for storage optimized it will cost around $1000 and for performance optimized it costs around $3000 to host this dataset.

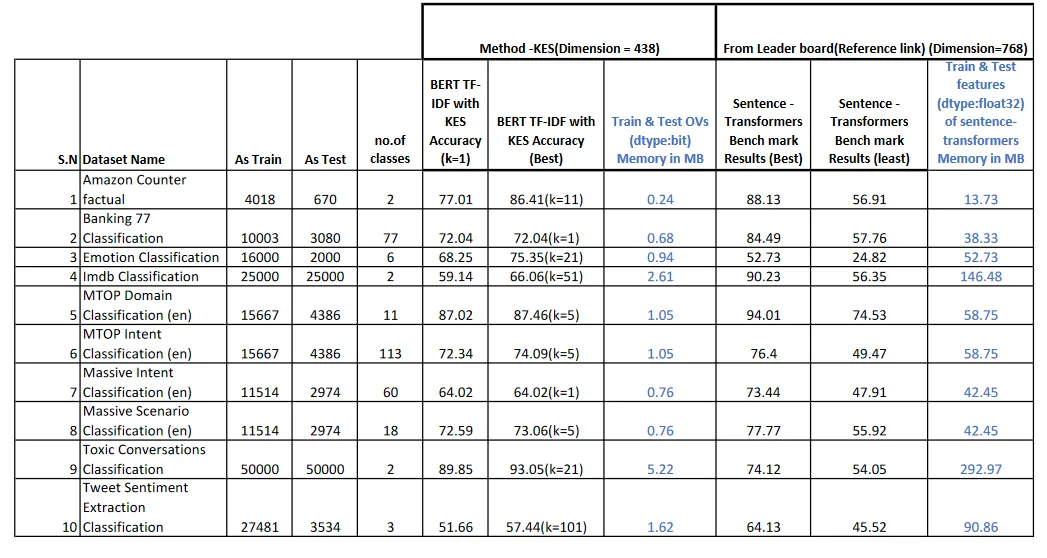
This was a good dataset to test out the efficacy of the Alpes KE Sieve algorithm. We built an embedding space based on sentence transformers all-mpnet-base-v2 model.
The advantage of the KE Sieve algorithm is that it can learn the space of any embeddings and replicate the results as we have seen in previous benchmarks.
{kind=link}
We created two models, one with 540 dimension bit embedding(small) and another with 2200 dimension bit embedding(large). We built these models on a single laptopn in around 20 hours.
Once we had the model, we were able to embed all the 36 million passages in 2GB and 10GB respectively for the small and large models.
It really was surprising that we can encode almost the whole of wikipedia data into 2GB. So we could perfrom semantic search on Wikipedia on consumer grade machines.
So you can now have local wikipedia vector search locally. Since the size is so small, we just used np.array and no vector databases. You can test it out in the link above and share your feedback.
The cost of hosting the above instance: ~$100
Since we have built the model on top of all-mpnet-base-v2 model, any other projects using this embedding can use our bit embedding as a drop in replacement and reduce inference costs by almost 10 times.
I found your article very interesting. Where can I get your model? Do you public the source code for this?